Bosch TAS16B2 machine à café Entièrement automatique Cafetière à dosette 0,7 L
Bosch TAS16B2. Type de produit: Cafetière à dosette, Type de cafetière: Entièrement automatique, Capacité du réservoir d'eau: 0,7 L, Type d'entrée à café: Capsule de café, Réservoir de café: Tasse. Type d'écran: LED. Puissance: 1400 W. Couleur du produit: Noir
Philips L’OR LM9012/50 machine à café Entièrement automatique Cafetière à dosette 0,8 L
Double Espresso, double plaisir.Découvrez la nouvelle machine à café L'OR Barista Sublime avec personnalisation du volume. Préparez deux espresso classiques à la fois ou un double espresso dans une seule tasse, grâce au système exclusif Double Espresso L'OR Barista.Nouvelle machine à café exclusive L'OR BaristaLa machine à café L'OR Barista est conçue pour fonctionner avec les capsules doubles (XXL) exclusives L'OR Barista et les capsules classiques L'OR Espresso.Assortiment de 9 capsules inclus dans l'emballageChaque appareil est fourni avec un assortiment de capsules :4 capsules classiques L'OR Espresso et 5 capsules doubles L'OR Barista.Préparez 2 cafés à la fois ou 1 café double dans une seule tasseLe système L'OR Barista vous permet de préparer deux tasses d'espresso ou un double espresso dans une seule tasse grâce aux capsules doubles (XXL) exclusives L'OR Barista. Savourez un ristretto à deux ou un double espresso seul.Jusqu'à 19 bars de pression pour un espresso parfaitSavourez le goût d'un véritable espresso. Le système L'OR Barista prépare le café à haute pression - jusqu'à 19 bars - pour garantir une qualité digne d'un véritable espresso.Des volumes de café réglables de 25 à 220 mlPréparez vos différents types de café grâce au système L'OR Barista. Savourez un ristretto, espresso, lungo et plus encore en utilisant des capsules classiques L'OR Espresso ou doublez votre plaisir grâce aux capsules doubles L'OR Barista (XXL).Personnalisez votre café préféréVous pouvez adapter votre machine en fonction de vos cafés. Il vous suffit de retirer le bac d'égouttement pour placer votre mug ou votre verre pour latte macchiato.Reconnaissance des capsules doubles, pour détecter automatiquement la taille des capsulesLa technologie de reconnaissance des capsules doubles (XXL) L'OR Barista détecte automatiquement la taille des capsules et sélectionne le réglage optimal pour chaque café.Bac d'égouttement réglable pour tasses de différentes taillesModifiez facilement la longueur de votre boisson selon vos goûts pour savourer votre tasse de café parfaite.Également compatible avec les capsules Nespresso®*La machine à café L'OR Barista est également compatible avec les capsules Nespresso®*.Compatible avec les capsules L'OR Espresso et L'OR BaristaUtilisez les nouvelles capsules doubles (XXL) exclusives L'OR Barista.Un grand choix de cafés : ristretto, espresso, lungo, etc.Un ristretto pour 2 ou un double espresso pour un.
introduction
L'apprentissage automatique est un sous-domaine de l'intelligence artificielle (IA). L'apprentissage automatique vise généralement à comprendre la structure des données et à les adapter à des modèles pouvant être compris et utilisés par les utilisateurs.
Bien que l’apprentissage automatique soit un domaine de l’informatique, il diffère des approches informatiques traditionnelles. En informatique traditionnelle, les algorithmes sont des ensembles d'instructions explicitement programmées utilisées par les ordinateurs pour calculer ou résoudre des problèmes. Les algorithmes d'apprentissage automatique permettent aux ordinateurs de se familiariser avec les entrées de données et d'utiliser l'analyse statistique afin de générer des valeurs comprises dans une plage spécifique. De ce fait, l’apprentissage automatique facilite l’informatique dans la construction de modèles à partir d’échantillons de données afin d’automatiser les processus de prise de décision en fonction des entrées de données.
Tout utilisateur de technologie a aujourd'hui bénéficié de l'apprentissage automatique. La technologie de reconnaissance faciale permet aux plates-formes de médias sociaux d'aider les utilisateurs à taguer et partager des photos d'amis. La technologie de reconnaissance optique de caractères (OCR) convertit les images de texte en caractères mobiles. Les moteurs de recommandation, basés sur l'apprentissage automatique, suggèrent quels films ou séries télévisées regarder ensuite en fonction des préférences de l'utilisateur. Les voitures autonomes nécessitant un apprentissage automatique de la navigation pourraient bientôt être disponibles pour les consommateurs.
L'apprentissage automatique est un domaine en constante évolution. C'est pourquoi vous devez garder à l'esprit certains points lorsque vous travaillez avec des méthodologies d'apprentissage automatique ou analysez l'impact des processus d'apprentissage automatique.
Dans ce didacticiel, nous examinerons les méthodes classiques d’apprentissage automatique (apprentissage supervisé et non supervisé), ainsi que les approches algorithmiques courantes en apprentissage automatique, notamment l’algorithme k plus proche voisin, l’apprentissage par arbre de décision et l’apprentissage en profondeur. Nous explorerons les langages de programmation les plus utilisés dans l’apprentissage automatique, en vous fournissant quelques-uns des attributs positifs et négatifs de chacun. En outre, nous discuterons des biais qui sont perpétués par des algorithmes d’apprentissage automatique et examinons ce qui peut être gardé à l’esprit pour éviter ces biais lors de la construction d’algorithmes.
Méthodes d'apprentissage automatique
Dans l'apprentissage automatique, les tâches sont généralement classées en grandes catégories. Ces catégories sont basées sur la manière dont l’apprentissage est reçu ou sur la manière dont le système mis au point reçoit un retour d’information.
Deux des méthodes d’apprentissage automatique les plus largement adoptées sont enseignement supervisé qui forme des algorithmes basés sur des exemples de données d'entrée et de sortie étiquetées par des humains, et apprentissage non supervisé qui fournit à l'algorithme aucune donnée étiquetée afin de lui permettre de trouver une structure dans ses données d'entrée. Explorons ces méthodes plus en détail.
Enseignement supervisé
En apprentissage supervisé, l'ordinateur est fourni avec des exemples d'entrées qui sont étiquetés avec les sorties souhaitées. Le but de cette méthode est que l’algorithme puisse «apprendre» en comparant sa sortie réelle avec les sorties «apprises» pour rechercher les erreurs et modifier le modèle en conséquence. L'apprentissage supervisé utilise donc des modèles pour prédire les valeurs d'étiquette sur des données supplémentaires non étiquetées.
Par exemple, avec un apprentissage supervisé, un algorithme peut être alimenté en données avec des images de requins étiquetés poisson et des images d'océans étiquetés comme eau. En s’entraînant à ces données, l’algorithme d’apprentissage supervisé devrait être en mesure d’identifier ultérieurement des images de requin non étiquetées. poisson et des images océaniques sans étiquette comme eau.
Un exemple courant d’apprentissage supervisé consiste à utiliser des données historiques pour prédire les événements futurs probables sur le plan statistique. Il peut utiliser les informations boursières historiques pour anticiper les fluctuations à venir ou être utilisé pour filtrer les spams. En apprentissage supervisé, les photos marquées de chiens peuvent être utilisées comme données d'entrée pour classer les photos non marquées de chiens.
Apprentissage non supervisé
Dans l'apprentissage non supervisé, les données ne sont pas étiquetées, de sorte que l'algorithme d'apprentissage est laissé pour rechercher les points communs entre ses données d'entrée. Les données non étiquetées étant plus abondantes que les données étiquetées, les méthodes d'apprentissage automatique facilitant l'apprentissage non supervisé sont particulièrement utiles.
L’objectif de l’apprentissage non supervisé peut être aussi simple que de découvrir des modèles cachés au sein d’un jeu de données, mais il peut également avoir pour objectif l’apprentissage des fonctionnalités, ce qui permet à la machine de calcul de découvrir automatiquement les représentations nécessaires pour classer les données brutes.
L'apprentissage non supervisé est couramment utilisé pour les données transactionnelles. Vous disposez peut-être d'un grand ensemble de données sur les clients et leurs achats, mais en tant qu'être humain, vous ne serez probablement pas en mesure de comprendre quels attributs similaires peuvent être tirés des profils de clients et de leurs types d'achats. Avec ces données intégrées dans un algorithme d'apprentissage non supervisé, il peut être déterminé que les femmes d'un certain groupe d'âge qui achètent des savons non parfumés sont susceptibles d'être enceintes. Une campagne de marketing liée aux produits destinés à la grossesse et au bébé peut donc être ciblée auprès de ce public. augmenter leur nombre d'achats.
Sans recevoir de réponse «correcte», les méthodes d'apprentissage non supervisées peuvent examiner des données complexes plus volumineuses et apparemment non liées afin de les organiser de manière potentiellement significative. L'apprentissage non supervisé est souvent utilisé pour la détection d'anomalies, y compris pour les achats frauduleux par carte de crédit, et pour les systèmes de recommandation qui recommandent les produits à acheter ensuite. Dans l'apprentissage non supervisé, les photos de chiens non étiquetées peuvent être utilisées comme données d'entrée pour que l'algorithme recherche les similarités et classe les photos de chiens ensemble.
Approches
En tant que domaine, l'apprentissage automatique est étroitement lié aux statistiques informatiques. Il est donc utile de disposer de connaissances de base en statistiques pour comprendre et exploiter les algorithmes d'apprentissage automatique.
Pour ceux qui n’ont peut-être pas étudié les statistiques, il peut être utile de définir d’abord la corrélation et la régression car il s’agit de techniques couramment utilisées pour étudier la relation entre les variables quantitatives. Corrélation est une mesure d'association entre deux variables qui ne sont désignées ni dépendantes ni indépendantes. Régression au niveau de base est utilisé pour examiner la relation entre une variable dépendante et une variable indépendante. Comme les statistiques de régression peuvent être utilisées pour anticiper la variable dépendante lorsque la variable indépendante est connue, la régression active les capacités de prédiction.
Des approches d'apprentissage automatique sont en développement continu. Pour ce qui nous concerne, nous allons passer en revue quelques-unes des approches populaires utilisées dans l’apprentissage automatique au moment de la rédaction.
k-voisin le plus proche
L'algorithme k-voisin le plus proche est un modèle de reconnaissance de modèle qui peut être utilisé à la fois pour la classification et la régression. Souvent abrégé en k-NN, le k dans k-voisin le plus proche est un entier positif, qui est généralement petit. Dans la classification ou la régression, l’entrée consistera en les k exemples d’entraînement les plus proches au sein d’un espace.
Nous allons nous concentrer sur la classification k-NN. Dans cette méthode, la sortie est l'appartenance à une classe. Ceci assignera un nouvel objet à la classe la plus commune parmi ses k plus proches voisins. Dans le cas de k = 1, l'objet est affecté à la classe du plus proche voisin.
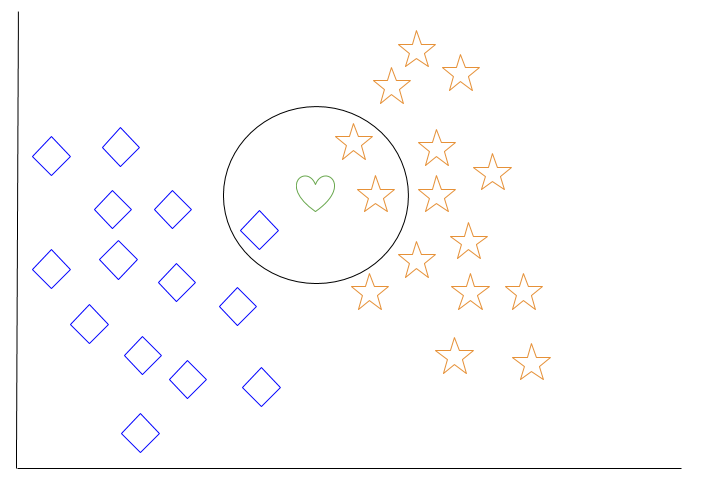
Voyons un exemple de k-voisin le plus proche. Dans le diagramme ci-dessous, il y a des objets en diamant bleu et des objets en étoile orange. Celles-ci appartiennent à deux classes distinctes: la classe des diamants et la classe des étoiles.
Lorsqu'un nouvel objet est ajouté à l'espace – dans ce cas, un cœur vert – nous voudrons que l'algorithme d'apprentissage automatique classifie le cœur dans une certaine classe.
Lorsque nous choisissons k = 3, l’algorithme trouvera les trois plus proches voisins du cœur vert afin de le classer dans la classe des diamants ou dans la classe des étoiles.
Dans notre diagramme, les trois plus proches voisins du cœur vert sont un diamant et deux étoiles. Par conséquent, l'algorithme classera le cœur avec la classe d'étoiles.
Parmi les algorithmes d'apprentissage machine les plus élémentaires, le k-voisin le plus proche est considéré comme un type «d'apprentissage paresseux», car la généralisation au-delà des données d'apprentissage ne se produit pas avant qu'une requête soit faite au système.
Apprentissage arbre de décision
Pour une utilisation générale, les arbres de décision sont utilisés pour représenter visuellement les décisions et montrer ou informer la prise de décision. Lorsque vous travaillez avec l'apprentissage automatique et l'exploration de données, les arbres de décision sont utilisés comme modèle prédictif. Ces modèles associent les observations relatives aux données aux conclusions relatives à la valeur cible des données.
L’apprentissage de l’arbre de décision a pour objectif de créer un modèle permettant de prédire la valeur d’une cible en fonction de variables d’entrée.
Dans le modèle prédictif, les attributs des données déterminés par observation sont représentés par les branches, tandis que les conclusions concernant la valeur cible des données sont représentées dans les feuilles.
Lorsque vous «apprenez» un arbre, les données source sont divisées en sous-ensembles en fonction d'un test de valeur d'attribut, répété de manière récursive sur chacun des sous-ensembles dérivés. Une fois que le sous-ensemble d'un nœud a la valeur équivalente à celle de la valeur cible, le processus de récurrence est terminé.
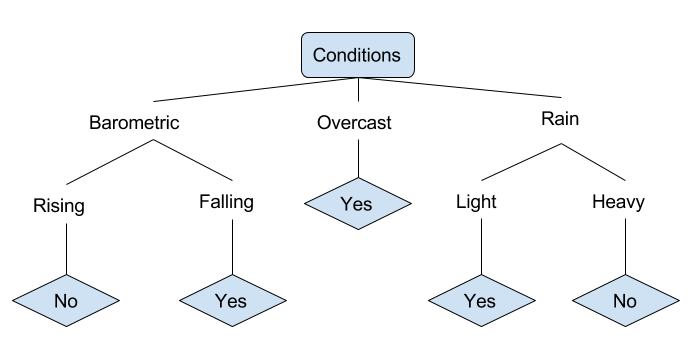
Examinons un exemple de diverses conditions pouvant déterminer si quelqu'un doit ou non aller pêcher. Cela inclut les conditions météorologiques ainsi que les conditions de pression barométrique.
Dans l'arbre de décision simplifié ci-dessus, un exemple est classé en le triant dans le noeud feuille approprié. Ceci retourne ensuite la classification associée à la feuille particulière, qui dans ce cas est une Oui ou un Non. L’arbre classe les conditions de la journée en fonction de son aptitude ou non à aller pêcher.
Un véritable ensemble de données d'arborescence de classification aurait beaucoup plus de fonctionnalités que ce qui est décrit ci-dessus, mais les relations devraient être simples à déterminer. Lorsque vous utilisez l'apprentissage par arbre de décision, plusieurs déterminations doivent être effectuées, notamment les fonctionnalités à choisir, les conditions à utiliser pour la scission et la compréhension du moment où l'arbre de décision atteint une fin claire.
L'apprentissage en profondeur
L'apprentissage en profondeur tente d'imiter la manière dont le cerveau humain peut transformer les stimuli lumineux et sonores en vision et en audition. Une architecture d'apprentissage en profondeur est inspirée des réseaux de neurones biologiques et consiste en plusieurs couches dans un réseau de neurones artificiel composé de matériel et de GPU.
L'apprentissage en profondeur utilise une cascade de couches d'unités de traitement non linéaires afin d'extraire ou de transformer des caractéristiques (ou représentations) des données. La sortie d'une couche sert d'entrée à la couche suivante. En apprentissage approfondi, les algorithmes peuvent être supervisés et utilisés pour classer les données, ou non supervisés et effectuer une analyse de modèle.
Parmi les algorithmes d’apprentissage automatique actuellement utilisés et développés, l’apprentissage en profondeur absorbe le plus de données et a été en mesure de battre l’être humain dans certaines tâches cognitives. En raison de ces attributs, l'apprentissage en profondeur est devenu l'approche avec un potentiel significatif dans l'espace de l'intelligence artificielle
La vision par ordinateur et la reconnaissance de la parole ont toutes deux réalisé d'importants progrès grâce aux approches d'apprentissage en profondeur. IBM Watson est un exemple bien connu de système qui exploite l'apprentissage en profondeur.
Langages de programmation
Lorsque vous choisissez une langue dans laquelle vous souhaitez vous spécialiser en apprentissage automatique, vous voudrez peut-être prendre en compte les compétences répertoriées dans les offres d'emploi actuelles, ainsi que les bibliothèques disponibles dans différentes langues pouvant être utilisées pour les processus d'apprentissage automatique.
D'après les données tirées des offres d'emploi sur Indeed.com de décembre 2016, on peut en déduire que Python est le langage de programmation le plus recherché dans le domaine professionnel de l'apprentissage automatique. Python est suivi de Java, puis de R, puis de C ++.
PythonLa popularité de ce produit pourrait être due au développement accru de cadres d’apprentissage en profondeur disponibles pour cette langue, notamment TensorFlow, PyTorch et Keras. En tant que langage doté d'une syntaxe lisible et pouvant être utilisé comme langage de script, Python se révèle puissant et simple à la fois pour le traitement préalable des données et le traitement direct des données. La bibliothèque d'apprentissage machine scikit-learn est construite sur plusieurs packages Python existants avec lesquels les développeurs Python sont peut-être déjà familiarisés, à savoir NumPy, SciPy et Matplotlib.
Pour commencer à utiliser Python, vous pouvez lire notre série de didacticiels sur «Comment coder en Python 3» ou plus particulièrement «Construire un classificateur d'apprentissage automatique en Python avec scikit-learn» ou «Comment effectuer un transfert de style neuronal avec Python 3 et PyTorch. ”
Java est largement utilisé dans la programmation d'entreprise et est généralement utilisé par les développeurs d'applications de bureau front-end qui travaillent également à l'apprentissage machine au niveau de l'entreprise. En général, ce n’est pas le premier choix pour les débutants en programmation qui souhaitent en savoir plus sur l’apprentissage automatique, mais est recommandé par ceux qui ont une formation en développement Java à appliquer à l’apprentissage automatique. En ce qui concerne les applications d’apprentissage automatique dans l’industrie, Java a tendance à être davantage utilisé que Python pour la sécurité du réseau, y compris dans les cas d’utilisation de la cyberattaque et de la détection de la fraude.
Deeplearning4j, une bibliothèque d'apprentissage en profondeur distribuée et open source écrite pour Java et Scala, fait partie des bibliothèques de machine learning pour Java. MALLET (MAéchine Lgagner pour LAnguagEToolkit) permet des applications d’apprentissage automatique du texte, notamment le traitement du langage naturel, la modélisation de sujets, la classification de documents et la mise en cluster; et Weka, une collection d’algorithmes d’apprentissage automatique à utiliser pour les tâches d’exploration de données.
R est un langage de programmation open-source utilisé principalement pour le calcul statistique. Il a gagné en popularité au cours des dernières années et est favorisé par de nombreux universitaires. R n'est généralement pas utilisé dans les environnements de production de l'industrie, mais a augmenté dans les applications industrielles en raison d'un intérêt accru pour la science des données. Les packages populaires pour l’apprentissage automatique en R incluent caret (abréviation de Classification UNEDakota du Nord RÉgression Training) pour la création de modèles prédictifs, randomForest pour la classification et la régression et e1071, qui inclut des fonctions pour les statistiques et la théorie des probabilités.
C ++ est la langue de choix pour l'apprentissage automatique et l'intelligence artificielle dans les applications de jeu ou de robot (y compris la locomotion de robot). Les développeurs de matériel informatique embarqué et les ingénieurs électroniques sont plus susceptibles de préférer le C ++ ou le C aux applications d'apprentissage automatique en raison de leurs compétences et de leur niveau de contrôle dans le langage. Certaines bibliothèques d'apprentissage machine que vous pouvez utiliser avec C ++ incluent mlpack, Dlib, une solution évolutive, offrant de nombreux algorithmes d'apprentissage machine, ainsi que le Shark modulaire et à code source ouvert.
Biais Humains
Bien que les données et l’analyse informatique puissent nous faire penser que nous recevons des informations objectives, ce n’est pas le cas; être basé sur des données ne signifie pas que les résultats de l'apprentissage automatique sont neutres. Le biais humain joue un rôle dans la manière dont les données sont collectées, organisées et, en dernière analyse, dans les algorithmes qui déterminent la manière dont l'apprentissage automatique interagira avec ces données.
Si, par exemple, des personnes fournissent des images de «poisson» en tant que données pour former un algorithme et choisissent en très grande majorité des images de poisson rouge, un ordinateur peut ne pas classer un requin comme un poisson. Cela créerait un biais contre les requins en tant que poissons, et les requins ne seraient pas comptés comme des poissons.
Lors de l'utilisation de photographies historiques de scientifiques comme données de formation, un ordinateur peut ne pas classer correctement les scientifiques qui sont aussi des personnes de couleur ou des femmes. En fait, des recherches récentes examinées par des pairs ont montré que l'IA et les programmes d'apprentissage automatique manifestaient un biais semblable à celui de l'homme, incluant des préjugés de race et de genre. Voir, par exemple, «La sémantique dérivée automatiquement des corpus de langage contient des biais humains» et «Les hommes aiment aussi les achats: réduire l'amplification du biais de genre en utilisant des contraintes de niveau corpus» [PDF].
L'apprentissage automatique étant de plus en plus utilisé par les entreprises, des préjugés non appréhendés peuvent perpétuer des problèmes systémiques susceptibles d'empêcher les personnes de bénéficier d'un prêt, de se voir présenter des offres d'emploi bien rémunérées ou de bénéficier d'options de livraison le jour même.
Étant donné que les préjugés humains peuvent avoir un impact négatif sur les autres, il est extrêmement important d’en prendre conscience et de s’efforcer de les éliminer le plus possible. Pour y parvenir, vous pouvez vous assurer que différentes personnes travaillent sur un projet et que diverses personnes la testent et la passent en revue. D'autres ont demandé à des tierces parties réglementaires de surveiller et de vérifier des algorithmes, de mettre en place des systèmes alternatifs capables de détecter les biais, ainsi que des examens éthiques dans le cadre de la planification de projets de science des données. Sensibiliser sur les préjugés, tenir compte de nos propres préjugés inconscients et structurer l'équité dans nos projets d'apprentissage automatique et nos pipelines peuvent contribuer à lutter contre les préjugés dans ce domaine.
Conclusion
Ce tutoriel a passé en revue certains cas d'utilisation de l'apprentissage automatique, des méthodes courantes et des approches populaires utilisées sur le terrain, des langages de programmation appropriés pour l'apprentissage automatique, et abordé certaines choses à garder à l'esprit en termes de réplication de biais inconscients dans des algorithmes.
L'apprentissage automatique étant un domaine en constante innovation, il est important de garder à l'esprit que les algorithmes, les méthodes et les approches continueront à évoluer.
En plus de lire nos tutoriels sur «Comment créer un classificateur d’apprentissage automatique en Python avec scikit-learn» ou «Comment effectuer un transfert de style neuronal avec Python 3 et PyTorch», vous pouvez en apprendre davantage sur le traitement des données dans le secteur de la technologie en: en lisant nos tutoriels d'analyse de données.
Pour offrir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations des appareils. Le fait de consentir à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou les ID uniques sur ce site. Le fait de ne pas consentir ou de retirer son consentement peut avoir un effet négatif sur certaines caractéristiques et fonctions.
Fonctionnel
Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’utilisateur.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’utilisateurs afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.

 Bosch TAS16B2 machine à café Entièrement automatique Cafetière à dosette 0,7 LBosch TAS16B2. Type de produit: Cafetière à dosette, Type de cafetière: Entièrement automatique, Capacité du réservoir d'eau: 0,7 L, Type d'entrée à café: Capsule de café, Réservoir de café: Tasse. Type d'écran: LED. Puissance: 1400 W. Couleur du produit: Noir
Bosch TAS16B2 machine à café Entièrement automatique Cafetière à dosette 0,7 LBosch TAS16B2. Type de produit: Cafetière à dosette, Type de cafetière: Entièrement automatique, Capacité du réservoir d'eau: 0,7 L, Type d'entrée à café: Capsule de café, Réservoir de café: Tasse. Type d'écran: LED. Puissance: 1400 W. Couleur du produit: Noir Philips L’OR LM9012/50 machine à café Entièrement automatique Cafetière à dosette 0,8 LDouble Espresso, double plaisir.Découvrez la nouvelle machine à café L'OR Barista Sublime avec personnalisation du volume. Préparez deux espresso classiques à la fois ou un double espresso dans une seule tasse, grâce au système exclusif Double Espresso L'OR Barista.Nouvelle machine à café exclusive L'OR BaristaLa machine à café L'OR Barista est conçue pour fonctionner avec les capsules doubles (XXL) exclusives L'OR Barista et les capsules classiques L'OR Espresso.Assortiment de 9 capsules inclus dans l'emballageChaque appareil est fourni avec un assortiment de capsules :4 capsules classiques L'OR Espresso et 5 capsules doubles L'OR Barista.Préparez 2 cafés à la fois ou 1 café double dans une seule tasseLe système L'OR Barista vous permet de préparer deux tasses d'espresso ou un double espresso dans une seule tasse grâce aux capsules doubles (XXL) exclusives L'OR Barista. Savourez un ristretto à deux ou un double espresso seul.Jusqu'à 19 bars de pression pour un espresso parfaitSavourez le goût d'un véritable espresso. Le système L'OR Barista prépare le café à haute pression - jusqu'à 19 bars - pour garantir une qualité digne d'un véritable espresso.Des volumes de café réglables de 25 à 220 mlPréparez vos différents types de café grâce au système L'OR Barista. Savourez un ristretto, espresso, lungo et plus encore en utilisant des capsules classiques L'OR Espresso ou doublez votre plaisir grâce aux capsules doubles L'OR Barista (XXL).Personnalisez votre café préféréVous pouvez adapter votre machine en fonction de vos cafés. Il vous suffit de retirer le bac d'égouttement pour placer votre mug ou votre verre pour latte macchiato.Reconnaissance des capsules doubles, pour détecter automatiquement la taille des capsulesLa technologie de reconnaissance des capsules doubles (XXL) L'OR Barista détecte automatiquement la taille des capsules et sélectionne le réglage optimal pour chaque café.Bac d'égouttement réglable pour tasses de différentes taillesModifiez facilement la longueur de votre boisson selon vos goûts pour savourer votre tasse de café parfaite.Également compatible avec les capsules Nespresso®*La machine à café L'OR Barista est également compatible avec les capsules Nespresso®*.Compatible avec les capsules L'OR Espresso et L'OR BaristaUtilisez les nouvelles capsules doubles (XXL) exclusives L'OR Barista.Un grand choix de cafés : ristretto, espresso, lungo, etc.Un ristretto pour 2 ou un double espresso pour un.
Philips L’OR LM9012/50 machine à café Entièrement automatique Cafetière à dosette 0,8 LDouble Espresso, double plaisir.Découvrez la nouvelle machine à café L'OR Barista Sublime avec personnalisation du volume. Préparez deux espresso classiques à la fois ou un double espresso dans une seule tasse, grâce au système exclusif Double Espresso L'OR Barista.Nouvelle machine à café exclusive L'OR BaristaLa machine à café L'OR Barista est conçue pour fonctionner avec les capsules doubles (XXL) exclusives L'OR Barista et les capsules classiques L'OR Espresso.Assortiment de 9 capsules inclus dans l'emballageChaque appareil est fourni avec un assortiment de capsules :4 capsules classiques L'OR Espresso et 5 capsules doubles L'OR Barista.Préparez 2 cafés à la fois ou 1 café double dans une seule tasseLe système L'OR Barista vous permet de préparer deux tasses d'espresso ou un double espresso dans une seule tasse grâce aux capsules doubles (XXL) exclusives L'OR Barista. Savourez un ristretto à deux ou un double espresso seul.Jusqu'à 19 bars de pression pour un espresso parfaitSavourez le goût d'un véritable espresso. Le système L'OR Barista prépare le café à haute pression - jusqu'à 19 bars - pour garantir une qualité digne d'un véritable espresso.Des volumes de café réglables de 25 à 220 mlPréparez vos différents types de café grâce au système L'OR Barista. Savourez un ristretto, espresso, lungo et plus encore en utilisant des capsules classiques L'OR Espresso ou doublez votre plaisir grâce aux capsules doubles L'OR Barista (XXL).Personnalisez votre café préféréVous pouvez adapter votre machine en fonction de vos cafés. Il vous suffit de retirer le bac d'égouttement pour placer votre mug ou votre verre pour latte macchiato.Reconnaissance des capsules doubles, pour détecter automatiquement la taille des capsulesLa technologie de reconnaissance des capsules doubles (XXL) L'OR Barista détecte automatiquement la taille des capsules et sélectionne le réglage optimal pour chaque café.Bac d'égouttement réglable pour tasses de différentes taillesModifiez facilement la longueur de votre boisson selon vos goûts pour savourer votre tasse de café parfaite.Également compatible avec les capsules Nespresso®*La machine à café L'OR Barista est également compatible avec les capsules Nespresso®*.Compatible avec les capsules L'OR Espresso et L'OR BaristaUtilisez les nouvelles capsules doubles (XXL) exclusives L'OR Barista.Un grand choix de cafés : ristretto, espresso, lungo, etc.Un ristretto pour 2 ou un double espresso pour un.