Machine Learning (ML) commence à prendre forme et reconnaît de plus en plus que ML peut jouer un rôle clé dans un large éventail d'applications critiques, telles que l'exploration de données, le traitement du langage naturel, la reconnaissance d'images et les systèmes experts. ML fournit des solutions potentielles dans tous ces domaines et plus, et est appelé à être un pilier de notre future civilisation.
L'offre de concepteurs ML compétents n'a pas encore répondu à cette demande. Une des principales raisons à cela est que ML est tout simplement délicat. Ce tutoriel présente les bases de la théorie de la maîtrise de l'apprentissage, énonce les thèmes et les concepts communs, facilite la compréhension de la logique et permet de se familiariser avec les bases de l'apprentissage automatique.
Qu'est-ce que l'apprentissage automatique?
Alors, qu'est-ce que «l'apprentissage par la machine» au juste? ML est en fait un lot de choses. Le domaine est assez vaste et se développe rapidement. Il est continuellement partitionné et subdivisé ad-nauseam en différentes sous-spécialités et types d’apprentissage automatique.
Il existe cependant quelques points communs fondamentaux, et le thème général est le mieux résumé par cette déclaration souvent citée faite par Arthur Samuel en 1959: “[Machine Learning is the] domaine d’études qui donne aux ordinateurs la possibilité d’apprendre sans être explicitement programmé. "
Et plus récemment, en 1997, Tom Mitchell a donné une définition «bien posée» qui s’est révélée plus utile pour les types d’ingénierie: "On dit qu'un programme informatique apprend de l'expérience E en ce qui concerne une tâche T et une mesure de performance P, si sa performance sur T, mesurée par P, s'améliore avec l'expérience E."
«On dit qu'un programme informatique apprend de l'expérience E en ce qui concerne une tâche T et une mesure de performance P, si sa performance sur T, mesurée par P, s'améliore avec l'expérience E.» – Tom Mitchell, Carnegie Mellon University
Ainsi, si vous souhaitez que votre programme prédit, par exemple, les modèles de trafic à une intersection achalandée (tâche T), vous pouvez l’exécuter via un algorithme d’apprentissage automatique avec des données sur les anciens modèles de trafic (expérience E) et, s’il a réussi à «apprendre ”, Il sera alors plus facile de prévoir les futurs modèles de trafic (mesure de performance P).
Cependant, la nature très complexe de nombreux problèmes du monde réel signifie souvent qu'inventer des algorithmes spécialisés permettant de les résoudre parfaitement à chaque fois est irréalisable, voire impossible. Des exemples de problèmes d’apprentissage automatique sont: «Ce cancer est-il?», «Quelle est la valeur marchande de cette maison?», «Lesquelles de ces personnes sont-elles bonnes amies?», «Ce moteur de fusée va-t-il exploser? ”,“ Cette personne appréciera-t-elle ce film? ”,“ Qui est-ce? ”,“ Qu'avez-vous dit? ”Et“ Comment pilotez-vous cette chose? ”. Tous ces problèmes sont d’excellentes cibles pour un projet de lutte contre le blanchiment d’argent et, dans les faits, le système a été appliqué avec succès à chacun d’eux.
ML résout des problèmes qui ne peuvent être résolus que par des moyens numériques.
Parmi les différents types de tâches de BC, une distinction cruciale est établie entre apprentissage supervisé et non supervisé:
Apprentissage machine supervisé: Le programme est «formé» sur un ensemble prédéfini d '«exemples de formation», ce qui facilite ensuite sa capacité à parvenir à une conclusion précise lorsque de nouvelles données sont fournies.
Apprentissage automatique non supervisé: Le programme reçoit beaucoup de données et doit y trouver des modèles et des relations.
Nous nous concentrerons principalement sur l’apprentissage supervisé ici, mais la fin de l’article inclut une brève discussion sur l’apprentissage non supervisé avec quelques liens pour ceux qui sont intéressés à approfondir le sujet.
Apprentissage machine supervisé
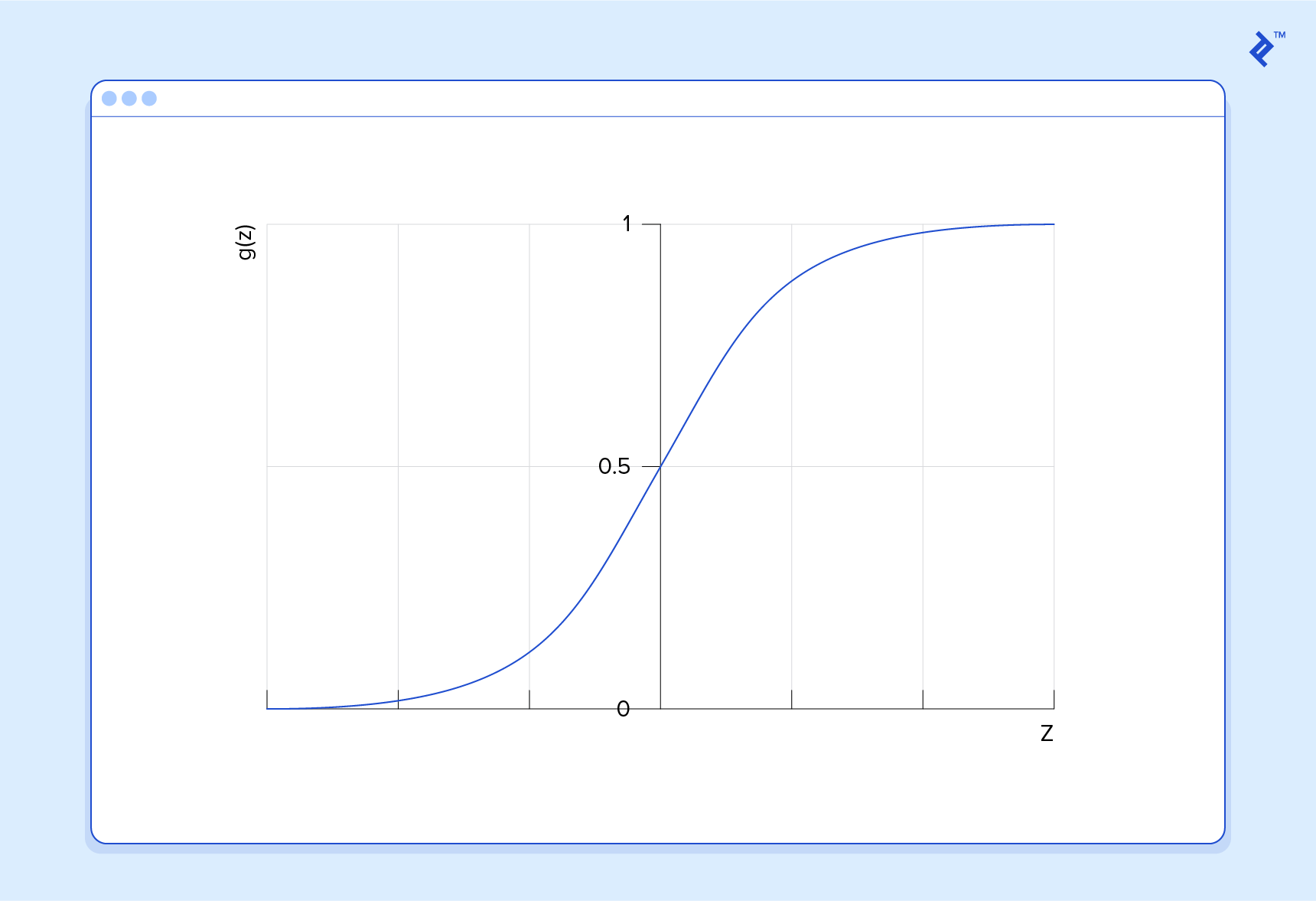
Dans la majorité des applications d’apprentissage supervisé, l’objectif ultime est de développer une fonction de prédiction parfaitement réglée. h (x) (parfois appelée "hypothèse"). L’apprentissage consiste à utiliser des algorithmes mathématiques sophistiqués pour optimiser cette fonction de telle sorte X sur un certain domaine (par exemple, la superficie d'une maison), il prédira avec précision une valeur intéressante h (x) (disons, prix du marché pour ladite maison).
En pratique, X représente presque toujours plusieurs points de données. Ainsi, par exemple, un prédicteur du prix du logement pourrait prendre non seulement une surface en pieds carrés (x1) mais aussi le nombre de chambres à coucher (x2), nombre de salles de bain (x3), nombre d'étages (x4), année de construction (x5), code postal (x6), et ainsi de suite. Déterminer les entrées à utiliser est une partie importante de la conception de ML. Toutefois, pour des raisons d’explication, il est plus facile de supposer qu’une seule valeur d’entrée est utilisée.
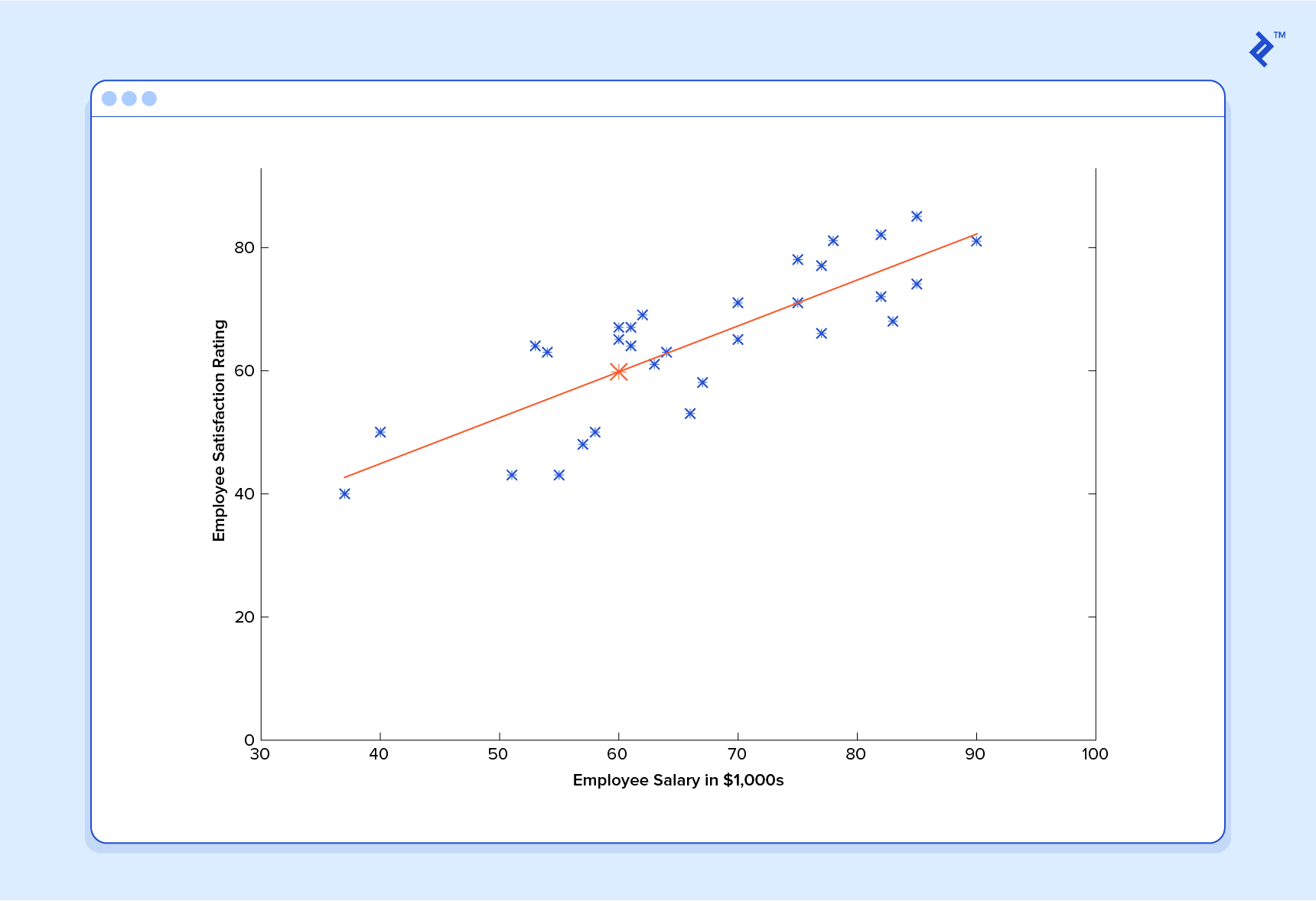
Alors, disons que notre prédicteur simple a cette forme:
où et sont des constantes. Notre objectif est de trouver les valeurs parfaites de et pour que notre prédicteur fonctionne le mieux possible.
Optimiser le prédicteur h (x) se fait en utilisant exemples de formation. Pour chaque exemple de formation, nous avons une valeur d'entrée x_train, pour lequel une sortie correspondante, y, est connu d'avance. Pour chaque exemple, nous trouvons la différence entre la valeur correcte connue yet notre valeur prévue h (x_train). Avec suffisamment d’exemples de formation, ces différences nous donnent un moyen utile de mesurer le «tort» de h (x). Nous pouvons alors modifier h (x) en peaufinant les valeurs de et pour le rendre "moins faux". Ce processus est répété jusqu'à ce que le système converge vers les meilleures valeurs pour et . De cette façon, le prédicteur est formé et est prêt à effectuer des prévisions dans le monde réel.
Exemples d'apprentissage automatique
Nous nous en tenons à des problèmes simples dans ce billet à des fins d’illustration, mais la raison pour laquelle ML existe, c’est parce que, dans le monde réel, les problèmes sont beaucoup plus complexes. Sur cet écran plat, nous pouvons tout au plus dessiner un ensemble de données tridimensionnelles, mais les problèmes de ML concernent généralement des données comportant des millions de dimensions et des fonctions de prédiction très complexes. ML résout des problèmes qui ne peuvent être résolus que par des moyens numériques.
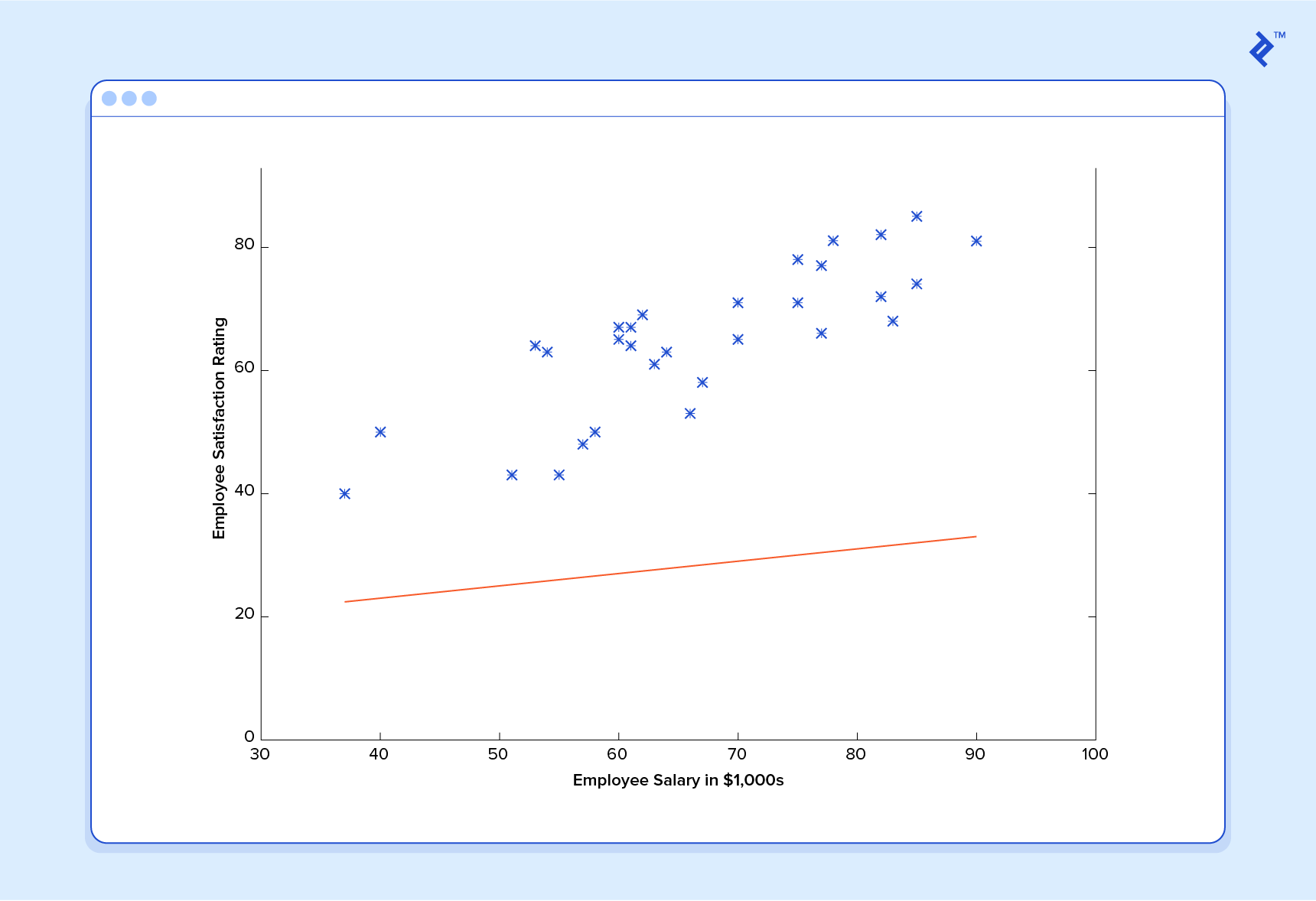
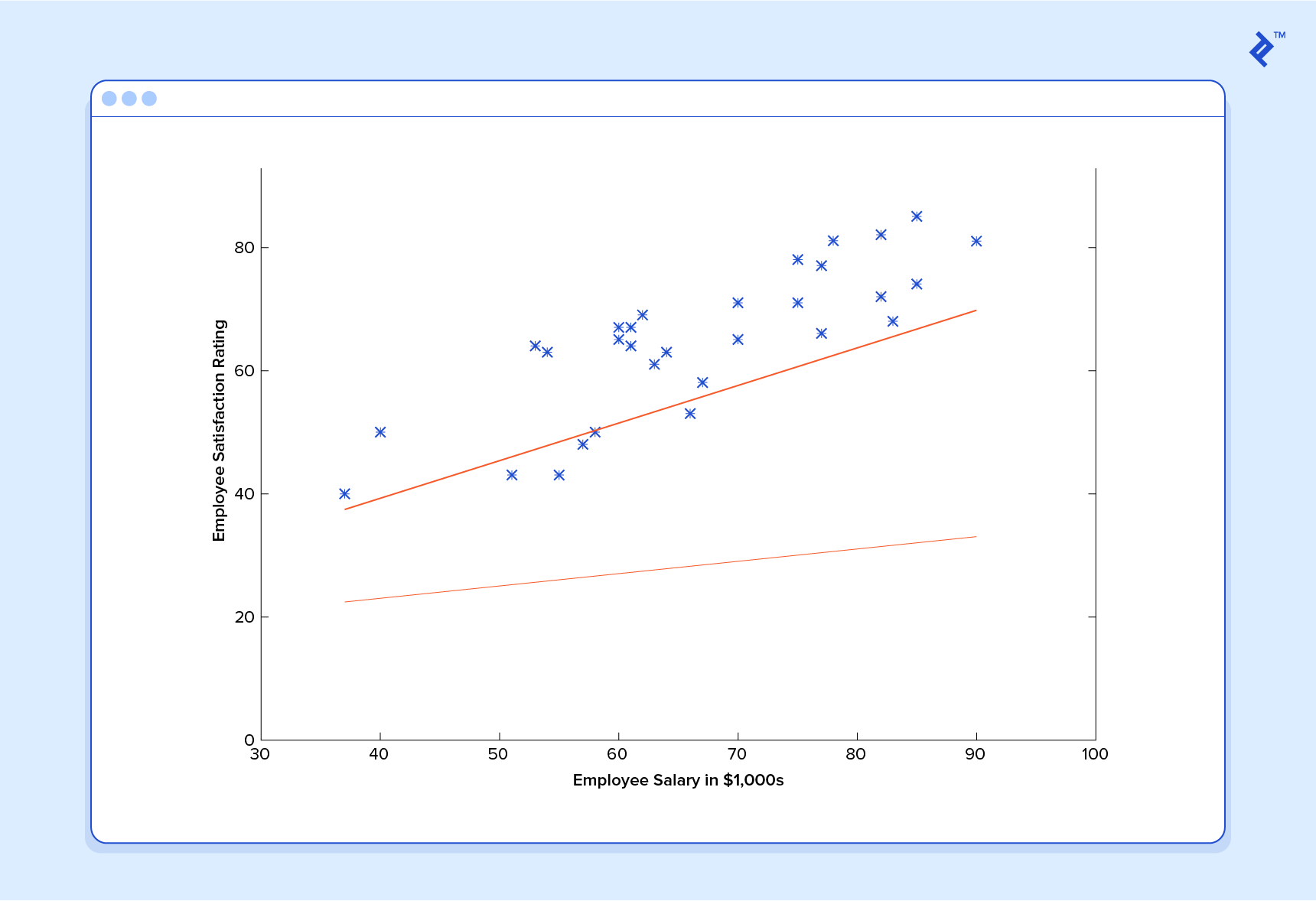
Dans cet esprit, examinons un exemple simple. Supposons que nous disposons des données de formation suivantes, dans lesquelles les employés de l'entreprise ont évalué leur satisfaction sur une échelle de 1 à 100:
Tout d'abord, remarquez que les données sont un peu bruitées. En d’autres termes, même si nous constatons une tendance (c’est-à-dire que la satisfaction des employés tend à augmenter à mesure que le salaire augmente), tout ne correspond pas parfaitement à la ligne droite. Ce sera toujours le cas avec les données du monde réel (et nous voulons absolument former notre machine en utilisant des données du monde réel!). Alors, comment pouvons-nous former une machine à prédire parfaitement le niveau de satisfaction d’un employé? La réponse, bien sûr, est que nous ne pouvons pas. L'objectif de ML n'est jamais de faire des suppositions «parfaites», car il traite dans des domaines où il n'y en a pas. Le but est de faire des suppositions suffisamment bonnes pour être utiles.
Cela rappelle un peu la fameuse déclaration du mathématicien et professeur de statistique britannique George E. P. Box selon laquelle «tous les modèles sont faux, mais certains sont utiles».
L'objectif de ML n'est jamais de faire des suppositions «parfaites», car il traite dans des domaines où il n'y en a pas. Le but est de faire des suppositions suffisamment bonnes pour être utiles.
L'apprentissage automatique s'appuie fortement sur les statistiques. Par exemple, lorsque nous entraînons notre machine à apprendre, nous devons lui donner un échantillon aléatoire statistiquement significatif comme données d’entraînement. Si l’entraînement n’est pas aléatoire, nous risquons d’avoir des modèles d’apprentissage automatique qui n’existent pas réellement. Et si l’ensemble de formation est trop petit (voir loi des grands nombres), nous n’en apprendrons pas assez et nous pourrions même arriver à des conclusions inexactes. Par exemple, tenter de prédire les modèles de satisfaction à l’échelle de l’entreprise à partir des données fournies par la haute direction seule serait probablement source d’erreurs.
Ceci étant dit, communiquons à notre machine les données que nous avons données ci-dessus et faisons-les apprendre. Nous devons d'abord initialiser notre prédicteur h (x) avec des valeurs raisonnables de et . Notre prédicteur ressemble maintenant à ceci lorsqu'il est placé sur notre ensemble d'entraînement:
Si nous demandons à ce prédicteur de satisfaire un employé gagnant 60 000 dollars, il prédirait une note de 27:
C’est évident que c’était une mauvaise idée et que cette machine ne sait pas grand chose.
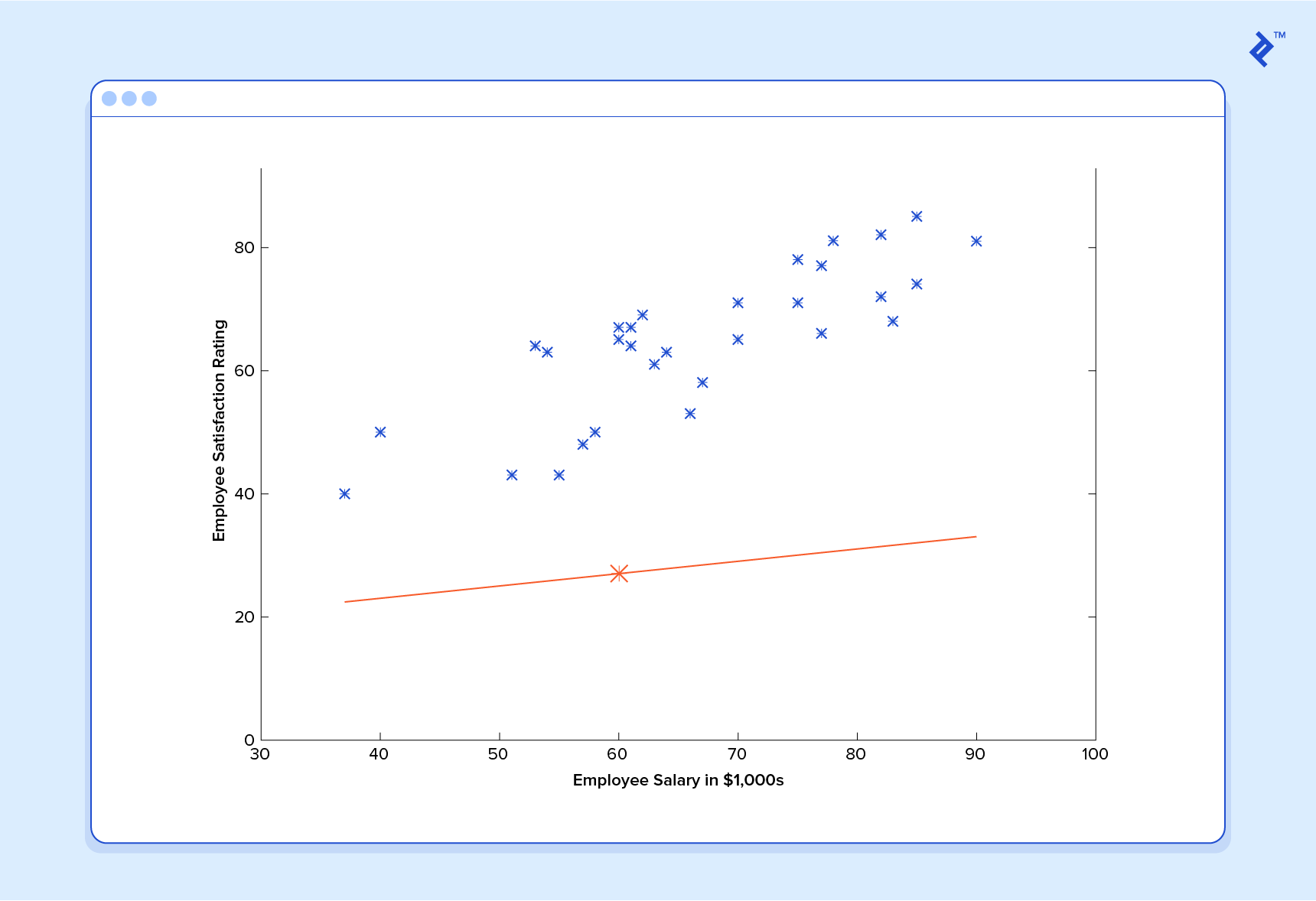
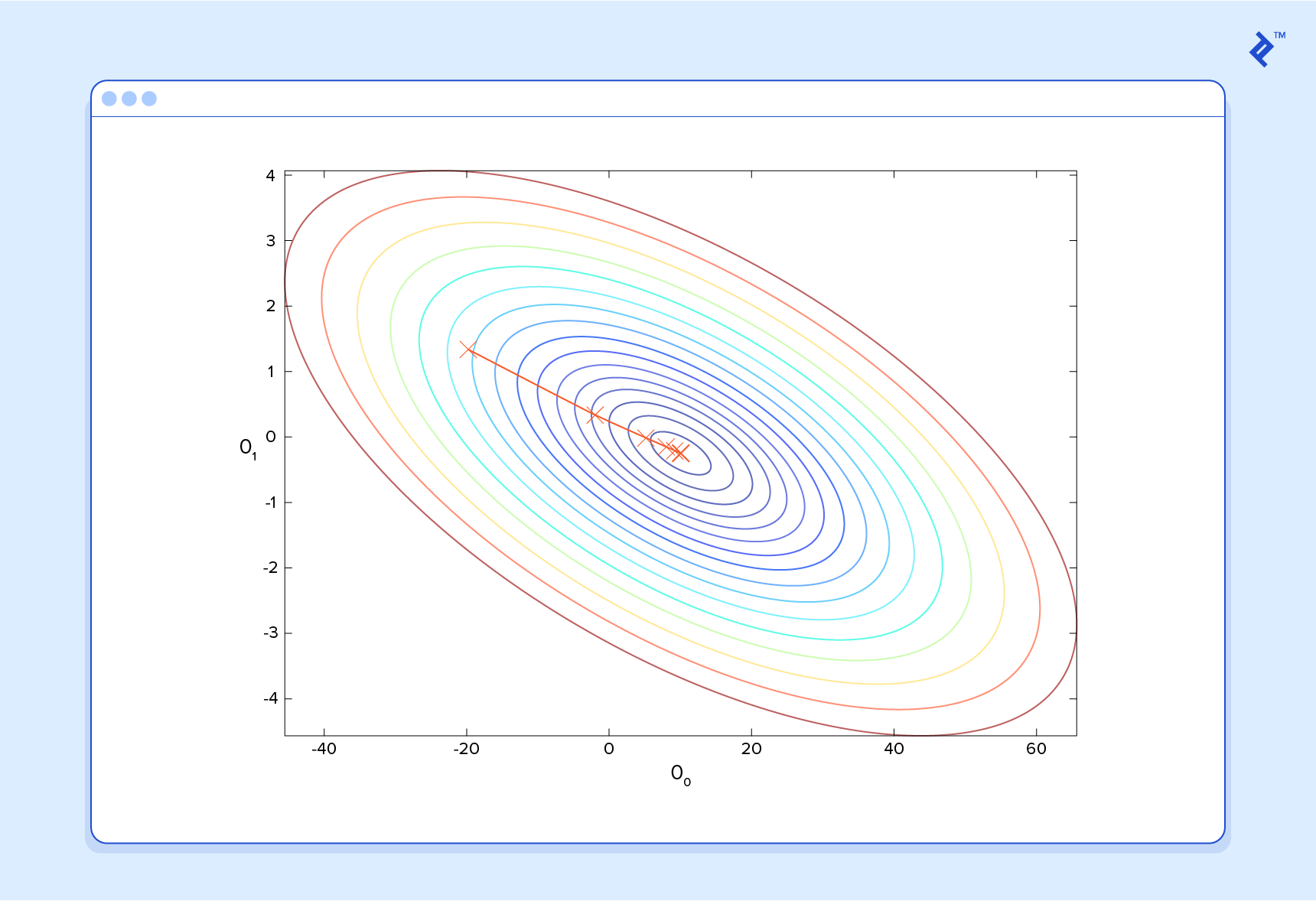
Alors maintenant, donnons à ce prédicteur tout les salaires de notre ensemble de formation et prenez les différences entre les cotes de satisfaction prédites qui en résultent et les cotes de satisfaction réelles des employés correspondants. Si nous effectuons un peu de magie mathématique (que je décrirai tout à l’heure), nous pourrons calculer avec une très grande certitude que des valeurs de 13,12 pour et 0,61 pour vont nous donner un meilleur prédicteur.
Et si nous répétons ce processus, disons 1 500 fois, notre prédicteur finira par ressembler à ceci:
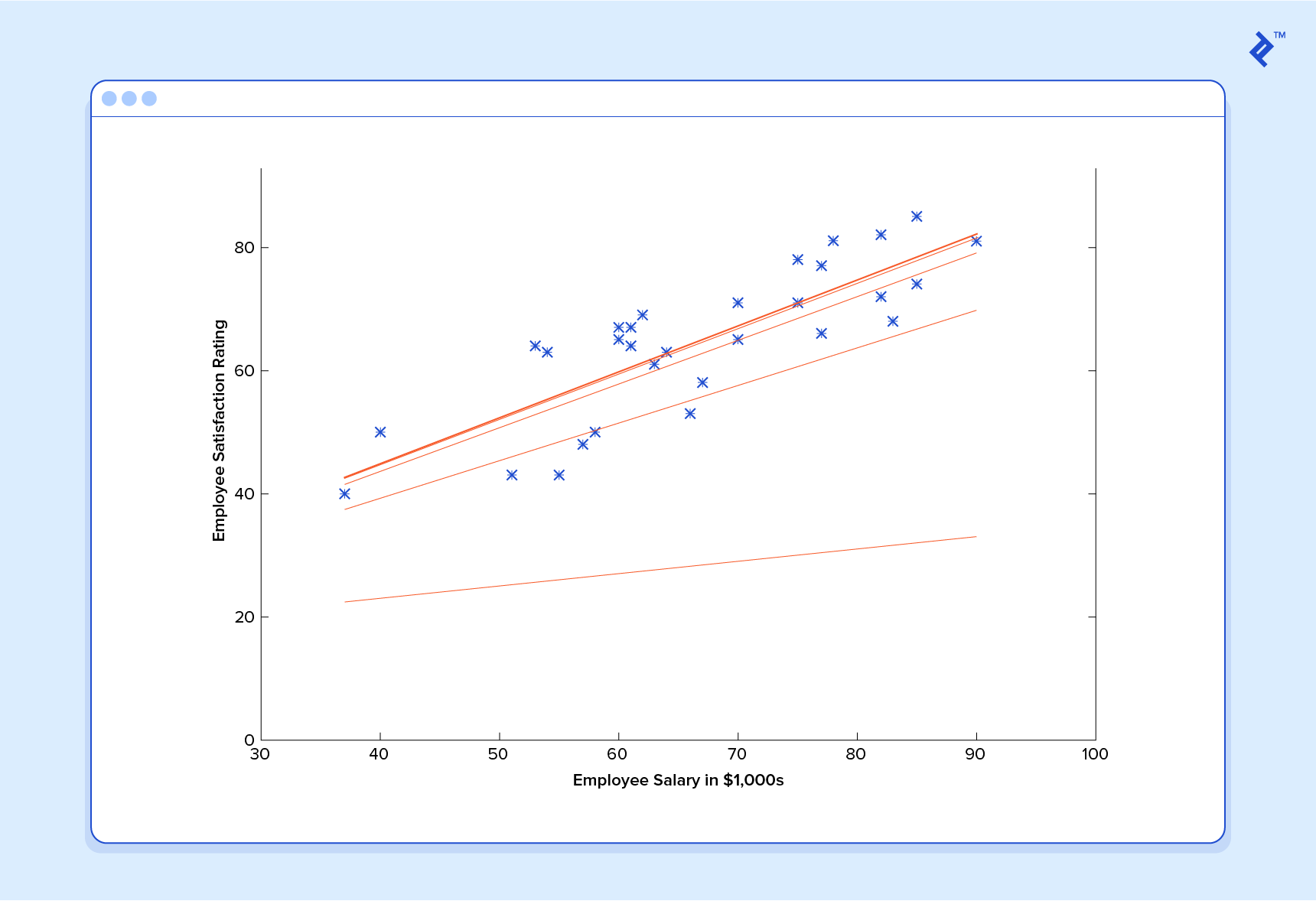
À ce stade, si nous répétons le processus, nous constaterons que et ne changera plus d’un montant appréciable et nous verrons donc que le système a convergé. Si nous n’avons commis aucune erreur, cela signifie que nous avons trouvé le prédicteur optimal. En conséquence, si nous demandons à nouveau à la machine le taux de satisfaction de l’employé qui gagne 60 000 dollars, elle prédisera un taux d’environ 60.
Maintenant, nous allons quelque part.
Régression par apprentissage automatique: remarque sur la complexité
L’exemple ci-dessus est techniquement un simple problème de régression linéaire univariée, qui peut en réalité être résolu en dérivant une simple équation normale et en sautant complètement ce processus de «réglage». Cependant, considérons un prédicteur qui ressemble à ceci:
Cette fonction prend des entrées dans quatre dimensions et utilise une variété de termes polynomiaux. Déduire une équation normale pour cette fonction est un défi important. De nombreux problèmes d’apprentissage automatique modernes prennent des milliers, voire des millions de dimensions de données pour établir des prévisions utilisant des centaines de coefficients. Prédire comment le génome d’un organisme sera exprimé ou à quoi ressemblera le climat dans cinquante ans sont des exemples de problèmes aussi complexes.
De nombreux problèmes modernes de ML nécessitent des milliers, voire des millions de dimensions de données pour établir des prévisions à l'aide de centaines de coefficients.
Heureusement, l'approche itérative adoptée par les systèmes ML est beaucoup plus résiliente face à une telle complexité. Au lieu d’utiliser la force brute, un système d’apprentissage automatique «fait son chemin» vers la réponse. Pour les gros problèmes, cela fonctionne beaucoup mieux. Bien que cela ne signifie pas que ML peut résoudre tous les problèmes arbitrairement complexes (cela ne peut pas être le cas), cela en fait un outil incroyablement flexible et puissant.
Descente de gradient – Minimiser «l’illongéité»
Examinons de plus près le fonctionnement de ce processus itératif. Dans l'exemple ci-dessus, comment pouvons-nous nous assurer et va mieux à chaque étape, et pas pire? La réponse réside dans notre «mesure de l'injustice» évoquée précédemment, avec un peu de calcul.
La mesure de l'injustice est connue sous le nom de fonction de coût (alias., fonction de perte), . L'entrée représente tous les coefficients que nous utilisons dans notre prédicteur. Donc dans notre cas, est vraiment la paire et . nous donne une mesure mathématique de la fausseté de notre prédicteur quand il utilise les valeurs données de et .
Le choix de la fonction de coût est un autre élément important d’un programme de blanchiment de capitaux. Dans «différents contextes», «avoir tort» peut signifier des choses très différentes. Dans notre exemple de satisfaction des employés, la norme bien établie est la fonction des moindres carrés linéaires:
Avec les moindres carrés, la pénalité pour une mauvaise devinette augmente quadratiquement avec la différence entre la devinette et la bonne réponse, de sorte qu'elle agit comme une mesure très «stricte» de l'injustice. La fonction de coût calcule une pénalité moyenne pour tous les exemples de formation.
Alors maintenant, nous voyons que notre objectif est de trouver et pour notre prédicteur h (x) telle que notre fonction de coût est aussi petit que possible. Nous faisons appel au pouvoir du calcul pour y parvenir.
Considérez le tracé suivant d'une fonction de coût pour un problème particulier d'apprentissage automatique:
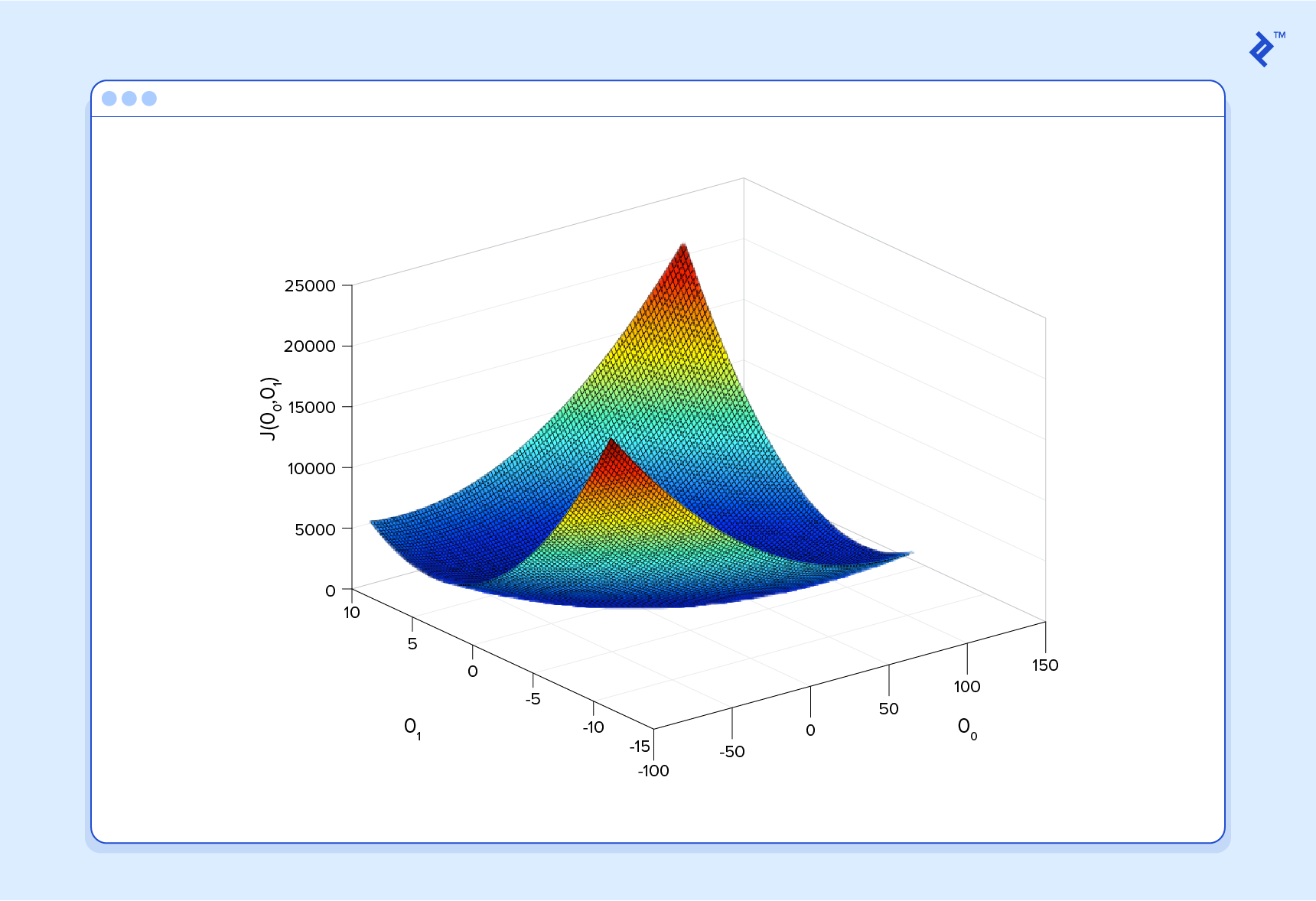
Ici, nous pouvons voir le coût associé à différentes valeurs de et . Nous pouvons voir que le graphique a un léger bol à sa forme. Le fond de la cuvette représente le coût le plus bas que notre prédicteur peut nous donner en fonction des données d’entraînement données. L’objectif est de «rouler en bas de la colline» et de trouver et correspondant à ce point.
C'est ici qu'intervient le calcul dans ce tutoriel d'apprentissage automatique. Pour que cette explication reste gérable, je n’écrirai pas les équations ici, mais ce que nous faisons est essentiellement la pente de , qui est la paire de dérivés de (un sur et un sur ). Le gradient sera différent pour chaque valeur différente de et , et nous dit ce que “la pente de la colline est” et, en particulier, “quel chemin est en bas”, pour ces particulier s. Par exemple, lorsque nous connectons nos valeurs actuelles de dans le gradient, cela peut nous dire qu’ajouter un peu à et en soustrayant un peu de nous mènera dans la direction de la fonction de coût-vallée. Par conséquent, nous ajoutons un peu à et soustrayez un peu de et voilà! Nous avons terminé un tour de notre algorithme d'apprentissage. Notre prédicteur mis à jour, h (x) = + x, retournera de meilleures prévisions qu'auparavant. Notre machine est maintenant un peu plus intelligente.
Ce processus d’alternance entre le calcul du gradient actuel et la mise à jour du s des résultats, est connu comme descente de gradient.
Cela couvre la théorie de base sous-jacente à la majorité des systèmes d’apprentissage automatique supervisé. Mais les concepts de base peuvent être appliqués de différentes manières, en fonction du problème à résoudre.
Problèmes de classification dans l'apprentissage automatique
Sous ML supervisé, les deux principales sous-catégories sont:
Systèmes d'apprentissage automatique par régression: Les systèmes où la valeur prédite se situe quelque part sur un spectre continu. Ces systèmes nous aident avec des questions de “combien?” Ou “combien?”.
Systèmes d'apprentissage automatique de classification: Les systèmes dans lesquels nous recherchons une prédiction oui ou non, tels que «Ce client est-il cancéreux?», «Ce cookie respecte-t-il nos normes de qualité?», Etc.
Il se trouve que la théorie sous-jacente du Machine Learning est plus ou moins la même. Les principales différences sont la conception du prédicteur h (x) et la conception de la fonction de coût .
Nos exemples jusqu’à présent se sont concentrés sur les problèmes de régression. Voyons donc maintenant un exemple de classification.
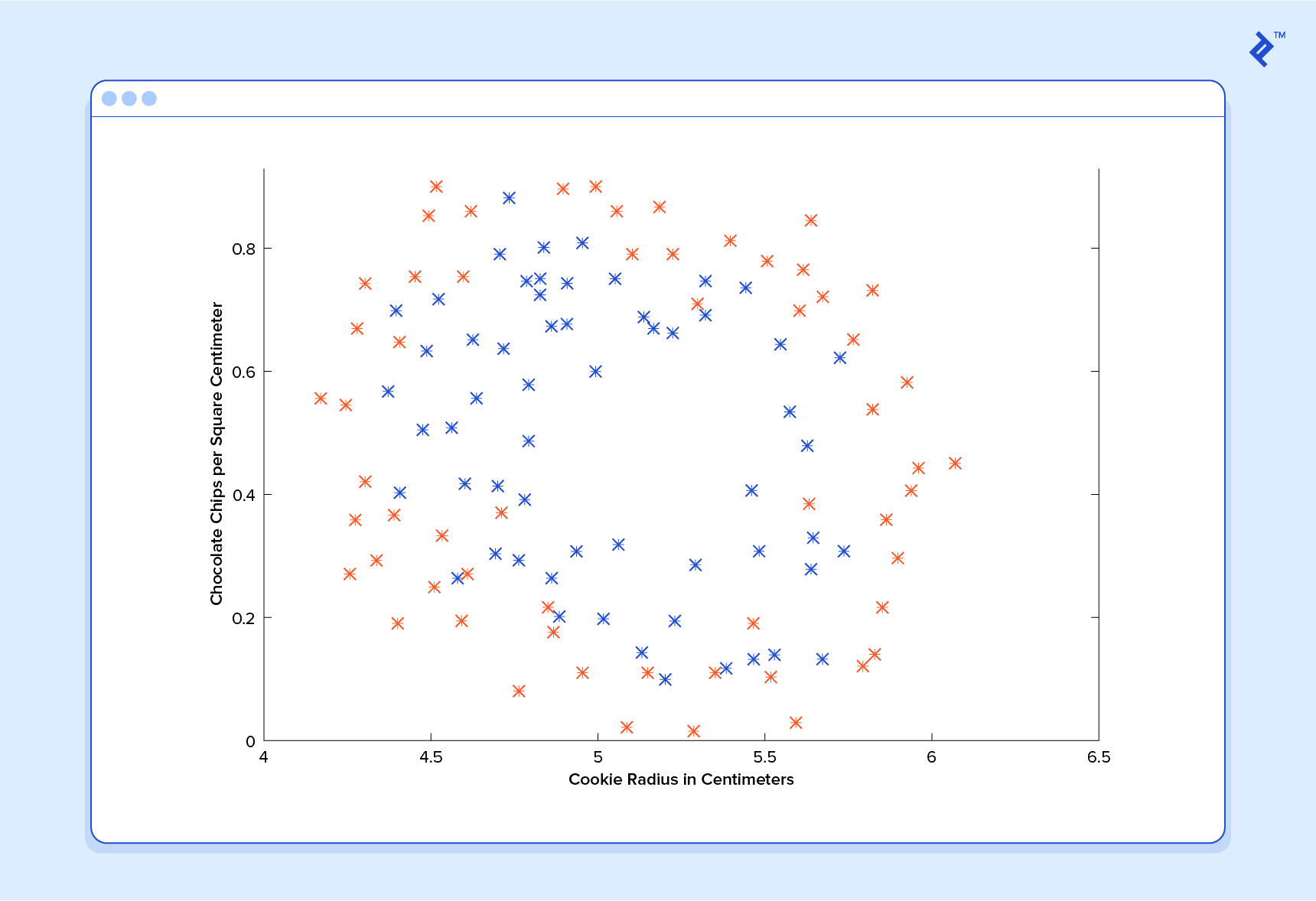
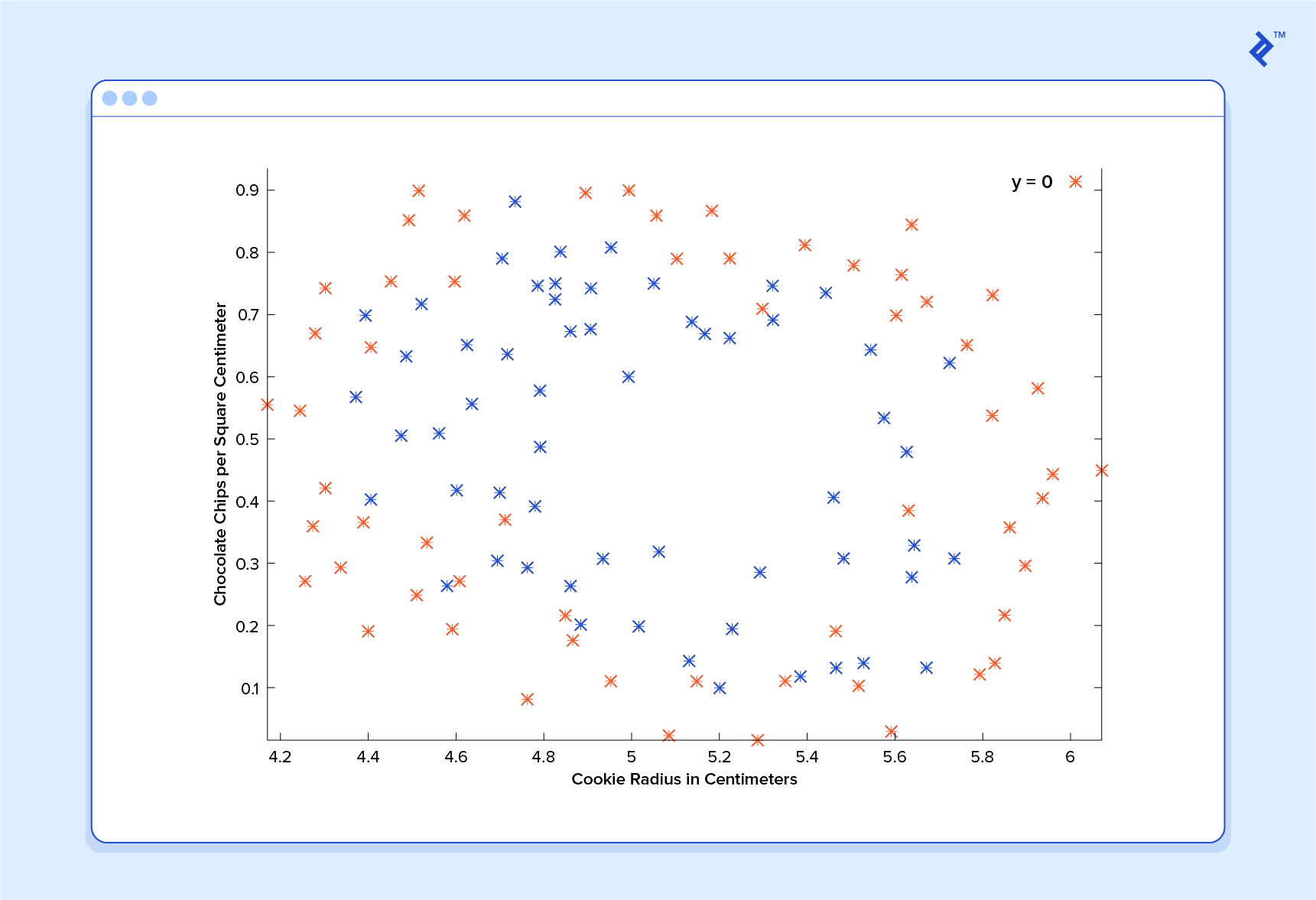
Voici les résultats d’une étude de contrôle de la qualité des cookies, dans laquelle les exemples de formation ont tous été étiquetés comme étant «un bon cookie» (y = 1) en bleu ou «mauvais cookie» (y = 0) en rouge.
En classification, un prédicteur de régression n’est pas très utile. Ce que nous voulons habituellement, c’est un prédicteur qui suppose une hypothèse comprise entre 0 et 1. Dans un classificateur de qualité de cookie, une prédiction de 1 représenterait une hypothèse très confiante sur le fait que le cookie est parfait et vous met l'eau à la bouche. Une prédiction de 0 représente une grande confiance dans le fait que le cookie est une source d'embarras pour l'industrie des cookies. Les valeurs comprises dans cet intervalle représentent moins de confiance. Nous pourrions donc concevoir notre système de telle sorte que la prédiction de 0,6 signifie «Homme, c'est un choix difficile, mais je vais y aller avec oui, vous pouvez vendre ce cookie», alors qu'une valeur exactement dans le milieu, à 0,5, pourrait représenter une incertitude totale. Ce n’est pas toujours ainsi que la confiance est répartie dans un classificateur, mais c’est une conception très courante qui fonctionne pour les besoins de notre illustration.
Il s’avère qu’une fonction intéressante capture bien ce comportement. On l’appelle la fonction sigmoïde, g (z), et ça ressemble à ça:
z est une représentation de nos entrées et coefficients, tels que:
de sorte que notre prédicteur devient:
Notez que la fonction sigmoïde transforme notre sortie dans la plage comprise entre 0 et 1.
La logique derrière la conception de la fonction de coût est également différente dans la classification. Encore une fois, nous nous demandons «qu'est-ce que cela signifie pour une supposition d'avoir tort?» Et cette fois une très bonne règle de base est que si la supposition correcte était 0 et que nous devinions 1, alors nous avions complètement et complètement tort, et vice-versa. . Comme vous ne pouvez pas avoir plus tort que tout à fait tort, la peine encourue dans ce cas est énorme. Alternativement, si la supposition correcte était 0 et que nous devinions 0, notre fonction de coût ne devrait pas ajouter de coût à chaque fois que cela se produit. Si la supposition était juste, mais nous n’étions pas complètement confiants (par exemple, y = 1, mais h (x) = 0,8), cela devrait engendrer un faible coût, et si notre estimation était fausse mais que nous n’étions pas totalement confiants (par exemple, y = 1 mais h (x) = 0,3), cela devrait entraîner des coûts importants, mais pas autant que si nous avions complètement tort.
Ce comportement est capturé par la fonction de journalisation, tel que:
Encore une fois, la fonction de coût nous donne le coût moyen de tous nos exemples de formation.
Nous avons donc décrit ici comment le prédicteur h (x) et la fonction de coût diffèrent entre la régression et la classification, mais la descente de gradient fonctionne toujours bien.
Un prédicteur de classification peut être visualisé en traçant la ligne de démarcation; c’est-à-dire la barrière où la prédiction passe d’un «oui» (prédiction supérieure à 0,5) à un «non» (prédiction inférieure à 0,5). Avec un système bien conçu, nos données de cookies peuvent générer une limite de classification ressemblant à ceci:
C’est une machine qui connaît très bien les cookies!
Une introduction aux réseaux de neurones
Aucune discussion sur l'apprentissage automatique ne serait complète sans mentionner au moins les réseaux de neurones. Les réseaux de neurones constituent non seulement un outil extrêmement puissant pour résoudre des problèmes très difficiles, mais ils offrent également des indications fascinantes sur le fonctionnement de notre propre cerveau, ainsi que des possibilités fascinantes de créer un jour des machines vraiment intelligentes.
Les réseaux de neurones sont bien adaptés aux modèles d'apprentissage automatique où le nombre d'entrées est gigantesque. Le coût informatique de la gestion d’un tel problème est trop élevé pour les types de systèmes décrits plus haut. Il s'avère toutefois que les réseaux de neurones peuvent être réglés efficacement à l’aide de techniques remarquablement similaires à la descente de gradient.
Une discussion approfondie sur les réseaux de neurones dépasse le cadre de ce tutoriel, mais je vous recommande de consulter notre précédent article sur le sujet.
Apprentissage automatique non supervisé
L'apprentissage automatique non supervisé est généralement chargé de rechercher des relations au sein de données. Aucun exemple de formation utilisé dans ce processus. Au lieu de cela, le système reçoit une série de données et est chargé de rechercher des modèles et des corrélations. Un bon exemple est l’identification de groupes d’amis très proches dans les données de réseaux sociaux.
Les algorithmes d’apprentissage automatique utilisés à cette fin sont très différents de ceux utilisés pour l’apprentissage supervisé et le sujet mérite son propre article. Cependant, pour que quelque chose se moque entre-temps, jetez un coup d'œil aux algorithmes de classification tels que k-means, ainsi qu'aux systèmes de réduction de dimensionnalité tels que l'analyse en composantes principales. Notre précédent article sur le Big Data aborde également un certain nombre de ces sujets de manière plus détaillée.
Conclusion
Nous avons couvert ici une grande partie de la théorie de base qui sous-tend le domaine de l’apprentissage automatique, mais bien entendu, nous n’avons à peine effleuré la surface.
N'oubliez pas que pour appliquer réellement les théories contenues dans cette introduction à des exemples réels d'apprentissage automatique, une compréhension beaucoup plus approfondie des sujets abordés dans le présent document est nécessaire. Il existe de nombreuses subtilités et pièges dans ML, et de nombreuses façons d’être égarés par ce qui semble être une machine à penser parfaitement réglée. Presque chaque partie de la théorie de base peut être jouée et modifiée à l'infini, et les résultats sont souvent fascinants. Beaucoup se développent dans de nouveaux domaines d'étude qui conviennent mieux à des problèmes particuliers.
Clairement, Machine Learning est un outil incroyablement puissant. Dans les années à venir, il promet de contribuer à résoudre certains de nos problèmes les plus urgents et à ouvrir de nouveaux horizons aux entreprises de science des données. La demande d'ingénieurs en apprentissage automatique ne fera que croître, offrant des chances incroyables de faire partie de quelque chose de grand. J'espère que vous envisagerez de participer à l'action!
Reconnaissance
Cet article s’appuie largement sur les enseignements du professeur Andrew Ng, professeur à Stanford, dans son cours gratuit et ouvert d’apprentissage automatique. Le cours couvre de manière approfondie tous les sujets abordés dans cet article et fournit des tonnes de conseils pratiques au praticien du ML. Je ne saurais trop recommander ce cours aux personnes intéressées à explorer davantage ce domaine fascinant.
Pour offrir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations des appareils. Le fait de consentir à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou les ID uniques sur ce site. Le fait de ne pas consentir ou de retirer son consentement peut avoir un effet négatif sur certaines caractéristiques et fonctions.
Fonctionnel
Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’utilisateur.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’utilisateurs afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.


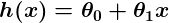
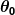 et
et 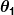 sont des constantes. Notre objectif est de trouver les valeurs parfaites de
sont des constantes. Notre objectif est de trouver les valeurs parfaites de 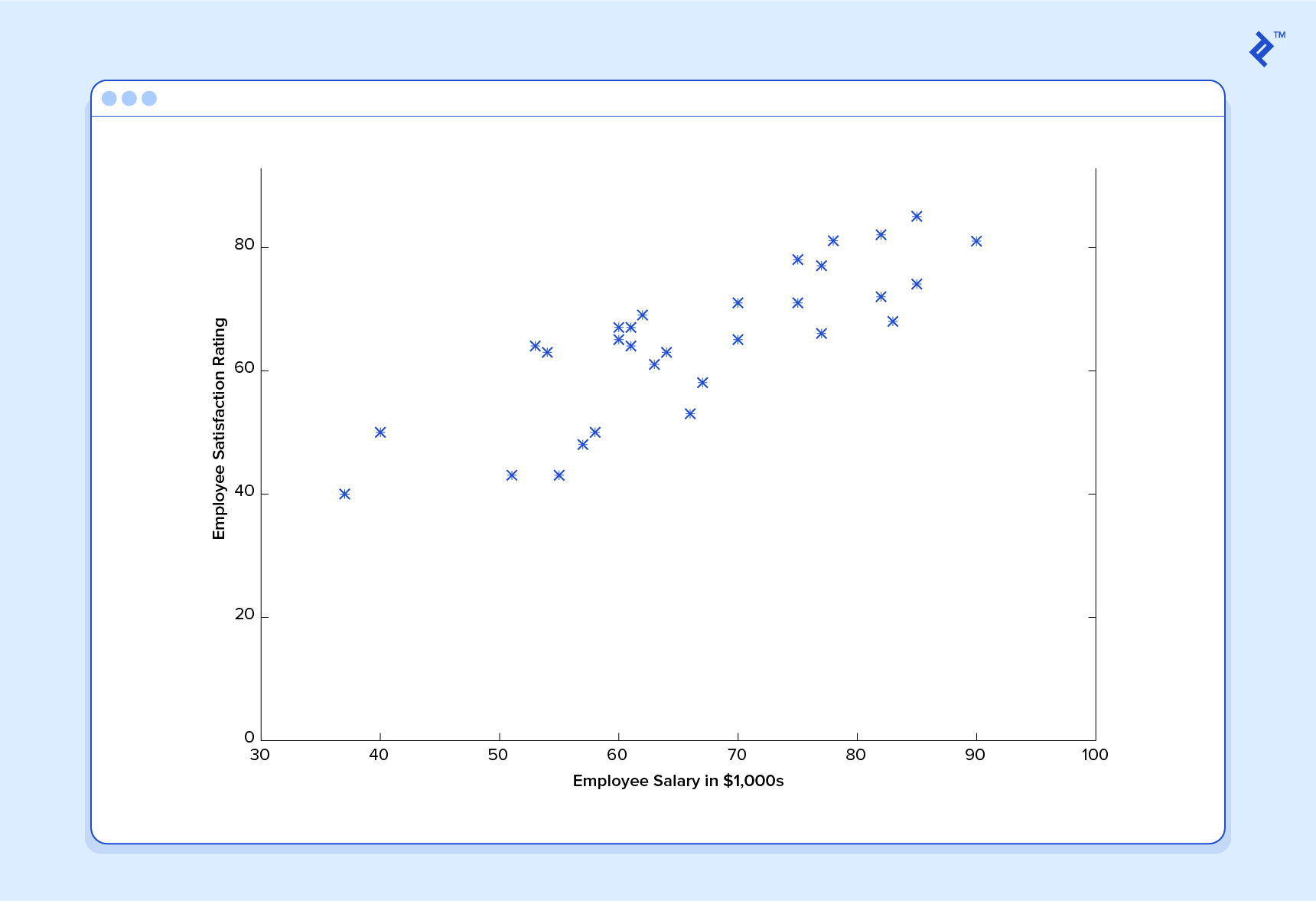
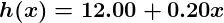
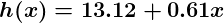
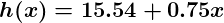
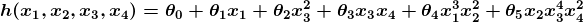
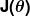 . L'entrée
. L'entrée 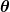 représente tous les coefficients que nous utilisons dans notre prédicteur. Donc dans notre cas,
représente tous les coefficients que nous utilisons dans notre prédicteur. Donc dans notre cas, 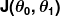 nous donne une mesure mathématique de la fausseté de notre prédicteur quand il utilise les valeurs données de
nous donne une mesure mathématique de la fausseté de notre prédicteur quand il utilise les valeurs données de 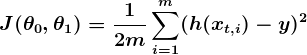
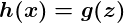
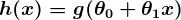
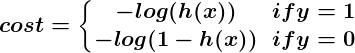
 \"dans Apple Books")




