L'apprentissage automatique, comme son nom l'indique, est la science de la programmation d'un ordinateur grâce auquel ils peuvent apprendre à partir de différents types de données. Une définition plus générale donnée par Arthur Samuel est la suivante: «L'apprentissage automatique est le domaine d'étude qui donne aux ordinateurs la capacité d'apprendre sans être explicitement programmé.» Ils sont généralement utilisés pour résoudre divers types de problèmes de la vie. Autrefois, les personnes effectuaient des tâches d'apprentissage automatique en codant manuellement tous les algorithmes, ainsi que les formules mathématiques et statistiques. Cela rendait le processus long, fastidieux et inefficace. Mais dans les temps modernes, il est devenu très facile et efficace par rapport aux systèmes anciens par diverses bibliothèques, frameworks et modules Python. Aujourd'hui, Python est l'un des langages de programmation les plus populaires pour cette tâche. Il a remplacé de nombreux langages dans l'industrie, notamment grâce à sa vaste collection de bibliothèques. Les bibliothèques Python utilisées dans Machine Learning sont les suivantes:
Numpy
Scipy
Scikit-apprendre
Theano
TensorFlow
Keras
PyTorch
Pandas
Matplotlib
Numpy
NumPy est une bibliothèque python très populaire pour le traitement de matrices et de tableaux multidimensionnels multidimensionnels, à l'aide d'une vaste collection de fonctions mathématiques de haut niveau. C'est très utile pour les calculs scientifiques fondamentaux en Machine Learning. Il est particulièrement utile pour l'algèbre linéaire, la transformée de Fourier et les capacités de nombres aléatoires. Les bibliothèques haut de gamme telles que TensorFlow utilisent NumPy en interne pour la manipulation de Tensors.
importationnumpy as np
X =np.array ([[[[[[[[1, 2],[[[[3, 4]])
y =np.array ([[[[[[[[5, 6],[[[[7, 8]])
v =np.array ([[[[9, dix])
w =np.array ([[[[11, 12])
impression(np.dot (v, w), " n")
impression(np.dot (x, v), " n")
impression(np.dot (x, y))
Sortie:
219
[29 67]
[[19 22]
[43 50]]
Pour plus de détails, voir Numpy.
SciPy
SciPy est une bibliothèque très populaire parmi les passionnés d’apprentissage automatique car elle contient différents modules d’optimisation, d’algèbre linéaire, d’intégration et de statistiques. Il existe une différence entre la bibliothèque SciPy et la pile SciPy. Le SciPy est l’un des principaux packages qui composent la pile SciPy. SciPy est également très utile pour la manipulation d'images.
Pour plus de détails, reportez-vous à la documentation.
Scikit-apprendre
Skikit-learn est l’une des bibliothèques ML les plus populaires pour les algorithmes ML classiques. Il est construit sur deux bibliothèques Python de base, à savoir, NumPy et SciPy. Scikit-learn supporte la plupart des algorithmes d'apprentissage supervisé et non supervisé. Scikit-learn peut également être utilisé pour l'exploration et l'analyse de données, ce qui en fait un excellent outil pour les débutants en ML.
Pour plus de détails, reportez-vous à la documentation.
Theano
Nous savons tous que l’apprentissage automatique se compose essentiellement de mathématiques et de statistiques. Theano est une bibliothèque Python populaire utilisée pour définir, évaluer et optimiser les expressions mathématiques impliquant des tableaux multidimensionnels de manière efficace. Ceci est réalisé en optimisant l'utilisation du processeur et du processeur graphique. Il est largement utilisé pour les tests unitaires et l'auto-vérification afin de détecter et de diagnostiquer différents types d'erreurs. Theano est une bibliothèque très puissante utilisée depuis longtemps dans des projets scientifiques de grande envergure, à forte intensité de calcul, mais assez simple et accessible pour être utilisée par des individus dans le cadre de leurs propres projets.
Pour plus de détails, reportez-vous à la documentation.
TensorFlow
TensorFlow est une bibliothèque open source très populaire pour le calcul numérique hautes performances développée par l'équipe Google Brain de Google. Comme son nom l'indique, Tensorflow est un framework qui implique la définition et l'exécution de calculs impliquant des tenseurs. Il peut former et gérer des réseaux de neurones profonds pouvant être utilisés pour développer plusieurs applications d'intelligence artificielle. TensorFlow est largement utilisé dans le domaine de la recherche et de l’application de l’apprentissage en profondeur.
importationtensorflow comme tf
x1 =tf.constant ([[[[1, 2, 3, 4])
x2 =tf.constant ([[[[5, 6, 7, 8])
résultat =tf.multiply (x1, x2)
sess =tf.Session ()
impression(sess.run (résultat))
sess.close ()
Sortie:
[ 5 12 21 32]
Pour plus de détails, reportez-vous à la documentation.
Keras
Keras est une bibliothèque très populaire d’apprentissage automatique pour Python. Il s’agit d’une API de réseaux de neurones de haut niveau capable de s’exécuter sur TensorFlow, CNTK ou Theano. Il peut fonctionner de manière transparente sur le processeur et le processeur graphique. Keras permet aux débutants de ML de créer et de concevoir un réseau de neurones. Une des meilleures choses à propos de Keras est qu’il permet un prototypage simple et rapide.
Pour plus de détails, reportez-vous à la documentation.
PyTorch
PyTorch est une bibliothèque populaire d'apprentissage Machine Open Source pour Python basée sur Torch, qui est une bibliothèque Machine Learning Open Source mise en œuvre en C avec un wrapper dans Lua. Il propose un vaste choix d'outils et de bibliothèques prenant en charge Computer Vision, le traitement du langage naturel (NLP) et de nombreux autres programmes ML. Il permet aux développeurs d'effectuer des calculs sur les tenseurs avec accélération GPU et facilite également la création de graphiques de calcul.
importationtorche
type =torche.flotte
dispositif =torch.device ("CPU")
N, D_in, H, D_out =64, 1000, 100, dix
X =torch.randn (N, D_in, périphérique =appareil, type =dtype)
y =torch.randn (N, D_out, périphérique =appareil, type =dtype)
w1 =torch.randn (D_in, H, périphérique =appareil, type =dtype)
w2 =torch.randn (H, D_out, périphérique =appareil, type =dtype)
Pour plus de détails, reportez-vous à la documentation.
Pandas
Pandas est une bibliothèque Python populaire pour l'analyse de données. Ce n'est pas directement lié à l'apprentissage automatique. Comme nous savons que le jeu de données doit être préparé avant la formation. Dans ce cas, les pandas sont pratiques car ils ont été développés spécifiquement pour l'extraction et la préparation de données. Il fournit des structures de données de haut niveau et de nombreux outils pour l'analyse des données. Il fournit de nombreuses méthodes intégrées pour tâtonner, combiner et filtrer les données.
importationpandas comme pd
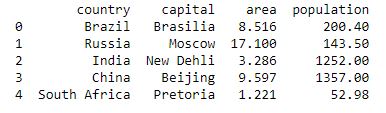
Les données ="pays":[[[["Brésil", "Russie", "Inde", "Chine", "Afrique du Sud"],
"Capitale":[[[["Brasilia", "Moscou", "New Dehli", "Pékin", "Pretoria"],
"surface":[[[[8.516, 17h10, 3.286, 9,597, 1.221],
"population":[[[[200,4, 143,5, 1252, 1357, 52,98]
table_données =pd.DataFrame (data)
impression(data_table)
Sortie: Pour plus de détails, reportez-vous aux pandas.
Matplotlib
Matpoltlib est une bibliothèque Python très populaire pour la visualisation de données. Comme les pandas, il n’est pas directement lié à l’apprentissage automatique. Cela s'avère particulièrement utile lorsqu'un programmeur souhaite visualiser les modèles dans les données. C'est une bibliothèque de tracé 2D utilisée pour créer des graphiques et des tracés 2D. Un module appelé pyplot facilite le traçage des programmeurs car il offre des fonctionnalités permettant de contrôler les styles de trait, les propriétés de police, les axes de formatage, etc. Il fournit différents types de graphiques et de tracés pour la visualisation des données, l'affichage, l'histogramme, les graphiques d'erreur, les discussions en barres. , etc,
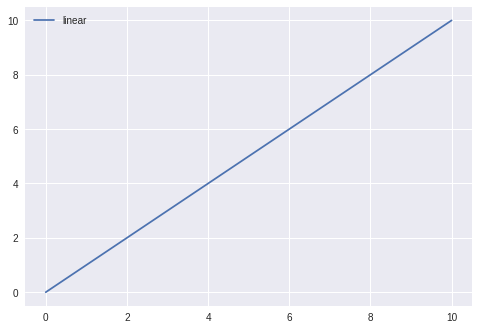
importationmatplotlib.pyplot en tant que plt
importationnumpy as np
X =np.linspace (0, dix, 100)
plt.plot (x, x, label ='linéaire')
plt.legend ()
plt.show ()
Sortie:
Pour plus de détails, reportez-vous à la documentation.
Un enfant ordinaire passionné par le codage
Si vous aimez GeeksforGeeks et souhaitez contribuer, vous pouvez également écrire un article en utilisant contribue.geeksforgeeks.org ou envoyer votre article par courrier électronique à l'adresse suivante: contribue@geeksforgeeks.org. Consultez votre article sur la page principale de GeeksforGeeks et aidez les autres Geeks.
S'il vous plaît, améliorez cet article si vous trouvez des erreurs en cliquant sur le bouton "Améliorer l'article" ci-dessous.
Pouce en l'air 4
Veuillez nous écrire à l'adresse suivante: contribue@geeksforgeeks.org pour signaler tout problème lié au contenu ci-dessus.
Pour offrir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations des appareils. Le fait de consentir à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou les ID uniques sur ce site. Le fait de ne pas consentir ou de retirer son consentement peut avoir un effet négatif sur certaines caractéristiques et fonctions.
Fonctionnel
Toujours activé
Le stockage ou l’accès technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
Le stockage ou l’accès technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’utilisateur.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
Le stockage ou l’accès technique est nécessaire pour créer des profils d’utilisateurs afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.